Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
Java 25 to change Windows file operation behaviors | InfoWorld
Technology insight for the enterpriseJava 25 to change Windows file operation behaviors 17 Jun 2025, 1:47 am
As part of a quality outreach, some changes are coming in the planned Java 25 release with regard to file operations on Windows. The File.delete command will no longer delete read-only files on Windows, and file operations on a path with a trailing space in a directory or file name will now fail consistently on Windows.
In a June 16 bulletin on Oracle’s inside.java blog, David Delabassee, Oracle director of Java relations, said File.delete in JDK 25 has been changed on Windows so it now fails and returns false for regular files when the DOS read-only attribute is set. Before JDK 25, File.delete would delete read-only files by removing the DOS read-only attribute before deletion was attempted. But because removing the attribute and deleting the file are not a single atomic operation, this could result in the file remaining, with modified attributes. Applications that depend on the previous behavior should be updated to clear the file attributes before deleting files, Delabassee said.
To make the transition easier, a system property has been introduced to restore the previous behavior. Running File.delete with -Djdk.io.File.allowDeleteReadOnlyFiles=true will remove the DOS read-only attribute prior to deleting the file, restoring the legacy behavior.
Also in JDK 25, file operations on a path with a trailing space in a directory or file name now fail consistently on Windows. For example, File::mkdir will return false, or File::createNewFile will throw IOException, if an element in the path has a trailing space, because path names such as these are not legal on Windows. Prior to JDK 25, operations on a file created from such an illegal abstract path name could appear to succeed when they did not, Delabassee said.
Now in a rampdown phase, JDK 25, a long-term support (LTS) release, is due to be generally available September 16.
{kind=link}
Databricks Data + AI Summit 2025: Five takeaways for data professionals, developers 16 Jun 2025, 2:19 pm
At Databricks’ Data + AI Summit 2025 last week, the company showcased a variety of generative and agentic AI improvements it is adding to its cloud-based data lakehouse platform — much as its rival Snowflake did the previous week.
With the two competitors’ events so close together, there’s little time for their product engineering teams to react to one another’s announcements. But that also means they’re under pressure to announce products that are far from ready for market, so as to avoid being scooped, perhaps explaining the plethora of features still in beta-testing or “preview.”
Here are some of the key new products and features announced at the conference that developers and data professionals may, one day, get to try for themselves:
It’s automation all the way down
Many enterprises are turning to AI agents to automate some of their processes. Databricks’ answer to that is Agent Bricks, a tool for automating the process of building agents.
It’s an integral part of the company’s Data Intelligence platform, and Databricks s pitching it as a way to take the complexity out of the process of building agents, as most enterprises don’t have either the time or the talent to go through an iterative process of building and matching an agent to a use case. It’s an area that, analysts say, has been ignored by rival vendors.
Another way that Databricks is setting its agent-building tools apart from those of rival vendors is that it is managing the agent lifecycle differently — not from within the builder interface but via Unity Catalog and MLflow 3.0.
Currently in beta testing, the interface supports the Model Context Protocol (MCP) and is expected to support Google’s A2A protocol in the future.
Eliminating data engineering bottlenecks
Another area in which Databricks is looking to help enterprises eliminate the data engineering bottlenecks that slow down AI projects is in data management. It previewed a data management tool powered by a generative AI assistant, Lakeflow Designer, to empower data analysts to take on tasks that are typically processed by data engineers.
Lakeflow Designer could be described as the “Canva of ETL,” offering instant, visual, AI-assisted development of data pipelines, but Databricks also sees it as a way to make collaboration between analysts and engineers easier.
Integrated into Lakeflow Declarative Pipelines, it also supports Git and DevOps flows, providing lineage, access control, and auditability.
Democratizing analytics for business users while maintaining governance
Databricks also previewed a no-code version of its Data Intelligence platform called Databricks One that provides AI and BI tools to non-technical users through a conversational user interface.
As part of the One platform, which is currently in private preview and can be accessed by Data Intelligence platform subscribers for free, Databricks is offering AI/BI Dashboards, Genie, and Databricks Apps along with built-in governance and security features via Unity Catalog and the Databricks IAM platform.
The AI/BI Dashboards will enable non-technical enterprise users to create and access data visualizations and perform advanced analytics without writing code. Genie, a conversational assistant, will allow users to ask questions about their data using natural language.
Databricks has also introduced a free edition of its Data Intelligence platform — a strategy to ensure that more data professionals and developers are using the platform.
Integrating Neon PostgreSQL into the Data Intelligence platform
One month after acquiring Neon for $1 billion, the cloud lakehouse provider has integrated Neon’s PostgreSQL architecture into its Data Intelligence Platform in the form of Lakebase.
The addition of the managed PostgreSQL database to the Data Intelligence platform will allow developers to quickly build and deploy AI agents without having to concurrently scale compute and storage while preventing performance bottlenecks, simplifying infrastructure issues, and reducing costs.
Integrated AI-assisted data migration with BladeBridge
Databricks has finally integrated the capabilities of BladeBridge into the Data Intelligence platform, after acquiring the company in February, in the form of Lakebridge — a free, AI-assisted tool to aid data migration to Databricks SQL.
Earlier this month, Databricks rival Snowflake also introduced a similar tool, named SnowCovert, that uses agents to help enterprises move their data, data warehouses, business intelligence (BI) reports, and code to Snowflake’s platform.
Other updates from Databricks included expanded capabilities of Unity Catalog in managing Apache Iceberg tables.
{kind=link}
The key to Oracle’s AI future 16 Jun 2025, 11:00 am
Oracle’s stock is finally catching up with its talk about cloud, fueled by surging infrastructure and AI demand. In its recent Q4 2025 earnings statement, the 46-year-old database giant surprised Wall Street with an 11% jump in revenue (to $15.9 billion) and bullish forecasts for the year ahead. Oracle’s stock promptly enjoyed its best week since 2001, leaping 24%. It’s relatively easy to please (and fool) investors, but there’s real substance in that 11% jump, and that substance is, at its foundation, all about data.
This is new for Oracle. I and others have criticized the company for being too slow to embrace cloud. As a result, both Microsoft Azure and Amazon Web Services pulled ahead of Oracle in database revenue a few years back as cloud became central to enterprise strategy.
Oracle, however, found a workaround.
For decades, Oracle Database has been the heart of the enterprise. It’s the system of record for much of the world’s most critical data. Instead of competing head-on with the likes of OpenAI and Google on foundation models, Oracle is offering something far more practical to its enterprise customers: the ability to run AI securely on their own data, within their own cloud environment. The new Oracle Database 23ai is a testament to this strategy, integrating AI capabilities directly into the database so that companies can get insights from their data without having to ship it off to a third-party service.
It’s smart, but it’s also not enough. Sustaining Oracle’s newfound momentum may require Oracle to succeed in an area where it has historically struggled: winning over developers. Developers, after all, are the people building the applications that will draw on all that Oracle data.
Cloud-based AI favors database vendors
Large language models (LLMs) have wowed us for the past few years with all they could do with massive quantities of publicly available data (even if the unwitting data providers, like Reddit, haven’t always been happy about that role). They’ve started to stumble, however, en route to true enterprise adoption, hampered by security concerns and the reality that as informed as they are by the internet, they’re incredibly dumb when it comes to a given enterprise because they have zero access to that data. Companies have tried to get around this problem with retrieval-augmented generation (RAG) and other tactics, but the real bonanza is waiting for the companies that can help enterprises apply AI to their data without having that data leave their secured infrastructure, whether running on premises or in the cloud.
A few vendors are figuring it out. Indeed, I’ve had a front-row seat to this phenomenon at MongoDB, where companies are finding it useful to store and search vector embeddings alongside operational data. Oracle is apparently discovering something similar, as noted on its earnings call, and is finally spending big on data centers to keep up with rising demand ($21 billion this year, which is more than 10 times what it was just four years ago).
Unsurprisingly, Oracle founder and CTO Larry Ellison couldn’t resist a bit of grandstanding on the earnings call, effectively arguing that when it comes to enterprise AI, Oracle has a home-field advantage. “These other companies say they have all the data, so they can do AI really well…. The only problem with that statement is they don’t have all the data. We do. We have most of the world’s valuable data. The vast majority of it is in an Oracle database.” It’s classic Ellison swagger, but there’s truth there: Oracle databases remain ubiquitous in large enterprises, storing troves of business-critical data.
Oracle is leveraging that position by making its database and cloud services “AI-centric.” Oracle’s pitch is that enterprises can use the data already sitting in their Oracle apps and databases to gain AI-driven insights securely and reliably without having to migrate everything to some new (and likely less secure) AI platform. “We are the key enabler for enterprises to use their own data and AI models,” Ellison argues. “No one else is doing that…. This is why our database business is going to grow dramatically.”
In Oracle’s view, the real gold rush in enterprise AI isn’t just hyping up the largest general AI models, but helping companies apply AI to their own data. Oracle has also been a bit less Oracle-like by embracing multicloud. Rather than insisting all workloads run on Oracle’s cloud (Oracle Cloud Infrastructure, or OCI), the company has inked partnerships to make Oracle Database available on AWS, Google Cloud, and Microsoft Azure. For enterprises concerned about data sovereignty, latency, or just avoiding single-vendor lock-in, that’s an attractive story.
But it’s not yet a complete story. For that, Oracle needs to figure out developers.
The missing piece
Eleven years ago I called out the missing piece in Oracle’s cloud ambitions: “Oracle … has built a cloud for its existing customers but not for developers who are building big data, internet of things, mobile, and other modern applications.” I doubled down on this theme, insisting that Oracle had failed to remedy “an almost complete lack of interest from developers.”
Plus ça change…
Oracle’s cloud growth so far has come largely from selling to the CIO, not the developer, signing big deals with companies that already trust Oracle for databases or apps, helping customers migrate existing Oracle-centric workloads, etc. That’s a perfectly valid strategy (and a lucrative one), but it leaves Oracle underexposed to the grassroots innovation happening in the broader developer community. Why does developer enthusiasm matter if Oracle can keep signing enterprise contracts? Because in the cloud era, developers are often the new enterprise kingmakers driving technology adoption.
Sure, the CIO of a large bank might sign a top-down deal with Oracle for an ERP system or database licenses, but it’s the developers and data scientists who are dreaming up the next generation of applications—the ones that don’t even exist yet. They have a world of cloud options at their fingertips. If they aren’t thinking of Oracle as a platform to create on, Oracle risks missing out on new workloads that aren’t already tied to its legacy footprint.
A modest proposal
It’s not my job to tell Oracle how to get its developer act together, but there are some obvious (if difficult) things it can and should do. Oracle doesn’t need to become “cool” in a Silicon Valley startup sense, but it does need to lower barriers so that a curious engineer or a small team can readily choose Oracle (including MySQL) for their next project. For example, years ago Oracle ceded MySQL’s dominant open source pole position to Postgres. It’s unclear whether the company would ever consider an open governance model for MySQL, but that may be the only way to put MySQL on equal footing. MySQL has great engineering, but it needs community.
Less culturally difficult, Oracle needs to keep improving onboarding and pricing to make it easy for developers to pick its cloud. One thing that made AWS popular with developers was the ability to swipe a credit card and get going immediately, with transparent usage-based pricing. Oracle has made progress here. OCI has a free tier and straightforward pricing for many services, but it can go further. For example, offering generous free credits for startups, individual developer accounts, or open-source projects could also seed grassroots adoption.
Oracle should also take a cue from Microsoft and increase its presence in developer communities and conferences, highlight success stories of “built on OCI” startups, and expand programs that engage developers directly. Oracle has started moving in this direction. At its CloudWorld 2024 conference, Oracle unveiled Oracle Code Assist (an AI-powered programming assistant for Java developers on OCI) and new features in its Oracle Kubernetes Engine to better support cloud-native apps and AI workloads. These are welcome additions. The key is to get such tools into developers’ hands and iterate based on feedback, which could be accomplished by an emboldened developer advocacy team.
Finally, Oracle should package its unique strengths in a way that allows developers to easily tap into them. For instance, Oracle’s expertise in databases and data management could be offered as developer-friendly services. The company’s new Oracle Database 23c has “AI” features (JSON relational duality, vector search, etc.) that sound great, but Oracle needs to ensure a developer can quickly provision a development instance of this database, load some data, and call an API or driver to start building an AI-powered app. In short, Oracle should make its cool tech easily accessible. If Oracle can give developers a taste of what its high-performance cloud and data systems can do—without a months-long enterprise procurement cycle—some will inevitably be impressed and advocate using Oracle for new projects.
Oracle is achieving something rare: a true second act in tech, decades into its life. By leaning into what it does best (databases, enterprise applications, and now high-performance cloud infrastructure) Oracle has made itself a contender in the age of AI. The next test will be whether the company can broaden its influence beyond the traditional enterprise IT shops that have always been its stronghold. If Oracle can find a way to engage developers on their own terms (without diluting its enterprise savvy), it could unlock another level of growth that makes today’s resurgence look modest.
{kind=link}
Understanding how data fabric enhances data security and governance 16 Jun 2025, 11:00 am
Data fabric is a powerful architectural approach for integrating and managing data across diverse sources and platforms.
As enterprises navigate increasingly complex data environments, the need for seamless data access coupled with robust security has never been more critical. Data fabric has the potential to enhance both data security as well as governance, but it’s not always a straight path for organizations to achieve the optimal outcome.
Understanding data fabric architecture
To get the most of data fabric, it’s important to first actually understand what it is and what it can actually provide to an organization. Unfortunately, defining data fabric can also be a challenge.
[ Related: Data mesh vs. data fabric vs. data virtualization: There’s a difference ]
“Thanks to multiple, often vendor-centric, definitions, there remains confusion in the industry about the precise nature of data fabric,” Matt Aslett, director, with global technology research and advisory firm ISG, told InfoWorld.
ISG defines data fabric as a technology-driven approach to automating data management and data governance in a distributed architecture that includes on-premises, cloud and hybrid environments. Aslett added that a common misconception is that enterprises must discard existing data platforms and management products to embrace data fabric.
Key elements of a data fabric architecture include the following:
- Metadata-driven data identification and classification
- Knowledge graphs
- Automated, ML-driven, data management.
“These capabilities provide the connective tissue that traverses disparate data silos and can complement the use of existing bespoke data tools by facilitating an abstracted view of data from across the business to support business intelligence and artificial intelligence initiatives that rely on the data unification,” Aslett said.
Data security challenges
Implementing a data fabric architecture presents several security challenges that enterprisemust address to ensure the integrity, confidentiality and availability of data assets.
Among the security challenges are these six::
Data silos and fragmentation
Despite the promise of integration, many organizations struggle with persistent data silos in their initial data fabric implementations.
“The biggest challenge is fragmentation; most enterprises operate across multiple cloud environments, each with its own security model, making unified governance incredibly complex,” Dipankar Sengupta, CEO of Digital Engineering Services at Sutherland Global told InfoWorld.
Compliance and regulatory complexity
Adhering to industry standards and regulations such as General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPAA) and California Consumer Privacy Act of 2018 (CCPA) is a significant challenge in data fabric implementations.
Different data types and sources may fall under different regulatory frameworks. As such, implementing consistent compliance measures across the entire fabric requires careful planning and execution.
Talent
According to Sengupta, the other blind spot is talent, with 82% of firms struggling to hire skilled data professionals.
Shadow IT
Shadow IT is also a persistent threat and challenge. According to Sengupta, some enterprises discover nearly 40% of their data exists outside governed environments. Proactively discovering and onboarding those data sources has become non-negotiable.
Data fragmentation
Another major obstacle to effective data security and governance is fragmentation.
“There are too many data silos to secure and govern, and too many tools required to get the job done,” Edward Calvesbert, Vice President, Product Management, for IBM watsonx.data, told InfoWorld.
IT complexity
According to Anil Inamdar, Global Head of Data Services at NetApp Instaclustr, the potential for data fabric security/governance challenges really begins with the complexity of the organization’s IT environment.
“If security is already inconsistent across hybrid or multi-cloud setups, teams will subsequently struggle to get their data fabric architecture as secure as it needs to be,” Inamdar said.
How data fabric enhances security
While there are some challenges, the reason why so many organizations choose to deploy data fabric is because it does significantly enhance data security and governance.
Data fabric architectures offer significant advantages for enhancing security when properly implemented across a number of different domains.
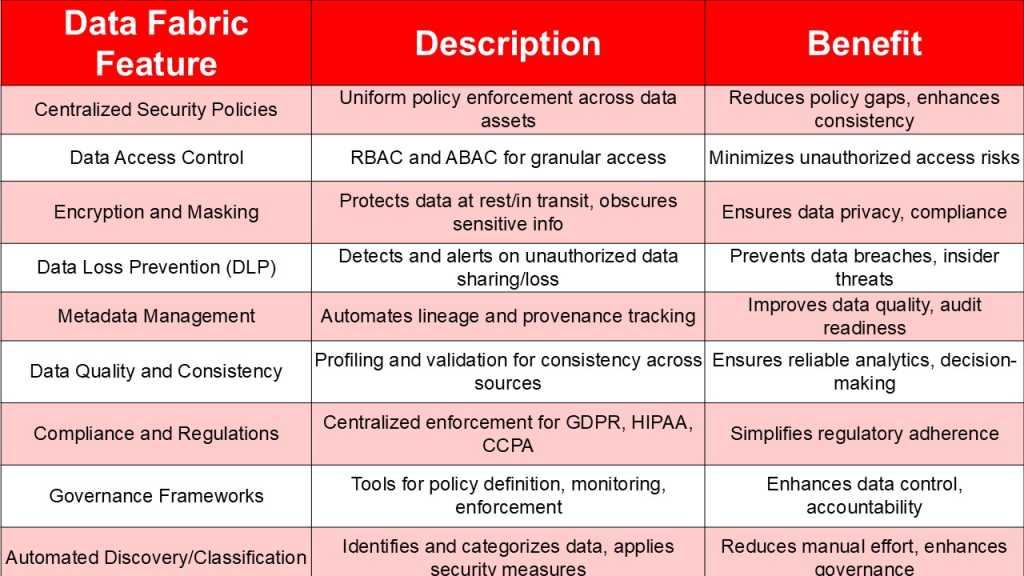
Centralized Security Policies
Organizations are using data fabric to fix the challenge of fragmentation. IBM’s Calvesbert noted that with data fabric organizations can create a centralized set of policies and rules capable of reaching all data within the organization. Policies and rules can be linked to any and all data assets through metadata like classifications, business terms, user groups, and roles – and then enforced automatically whenever data is accessed or moved.
Regulatory compliance
A data fabric deepens organizations’ understanding and control of their data and consumption patterns. “With this deeper understanding, organizations can easily detect sensitive data and workloads in potential violation of GDPR, CCPA, HIPAA and similar regulations,” Calvesbert commented. “With deeper control, organizations can then apply the necessary data governance and security measures in near real time to remain compliant.”
Metadata management
Automated metadata management and data cataloging are integral components and benefits of data fabric.
“It’s a big deal, because when metadata is automatically tagged and tracked across both cloud and on-prem environments, you are getting the level of visibility that is going to make security folks and compliance officers happy,” NetApp’s Inamdar commented. “Automating this process within a data fabric creates that digital breadcrumb trail that follows data wherever it goes.”
Automated data discovery and classification
Automated tools within data fabric discover and classify data, reducing manual effort and enhancing governance. This involves identifying sensitive data across environments, categorizing it and applying appropriate security measures.
Data access control and authorization
Data fabric supports granular access control through Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC), ensuring only authorized users can access sensitive data. This is vital for minimizing unauthorized access risks, with mechanisms like dynamic masking complementing these controls.
Data encryption and masking
Data fabric facilitates data encryption for protection at rest and in transit and data masking to obscure sensitive information. Encryption transforms data so it’s not transparent and available for anyone to look at, while masking replaces data with realistic but fake values, ensuring privacy.
Data governance frameworks
Data fabric supports implementing and enforcing data governance frameworks, providing tools for policy definition, monitoring, and enforcement. This ensures data is managed according to organizational policies, enhancing control and accountability.
IDG
Why data validation is critical for data fabric success
Data security and governance inside a data fabric shouldn’t just be about controlling access to data, it should also come with some form of data validation.
The cliched saying “garbage-in, garbage-out” is all too true when it comes to data. After all, what’s the point of ensuring security and governance on data that isn’t valid in the first place?
“Validating the quality and consistency of data is essential to establishing trust and encouraging data usage for both BI and AI projects,” Alslett said.
So how can and should enterprises use data validation within a data fabric? Sutherland Global’s Sengupta commented that the most effective validation strategies he has seen start with pushing checks as close to the source as possible. He noted that validating data upfront —rather than downstream — has helped reduce error propagation by over 50% in large-scale implementations. This distributed approach improves accuracy and lightens the processing load later in the pipeline.
Machine learning is playing a growing role as well. Statistical baselines and anomaly detection models can flag issues that rigid rule-based systems often miss. In one case cited by Sengupta this approach helped increase trust in critical data assets by nearly 80%.
“What’s often overlooked, though, is the value of context-aware validation—cross-domain consistency checks can expose subtle misalignments that may look fine in isolation,” Sengupta said. “For real-time use cases, stream validation ensures time-sensitive data is assessed in-flight, with accuracy rates approaching 99.8%.”
Benefits and use cases: data fabric in the real world
The real world impact of data fabric is impressive. While it can often just be used as a marketing term by vendors, there is tangible return on investment opportunities too.
“In our work with large enterprises, the most tangible impact of data fabric initiatives comes from their ability to speed up access to trustworthy data, safely and at scale,” Sengupta said.
For instance, a global financial institution reduced its regulatory reporting time by 78% and accelerated access provisioning by 60% after re-architecting its data governance model around unified security policies.
In healthcare, a provider network improved patient data accuracy from 87% to 99%, while also cutting integration time for new data sources by 45%, a critical gain when onboarding new partners or navigating compliance audits.
A manufacturing client saw a 52% drop in supply chain data errors and significantly improved the processing of IoT sensor data, boosting integration speed by 68%.
In retail, better orchestration of policies and quality controls translated into 85% faster delivery of customer insights, a 3x increase in analyst productivity, and a 30% reduction in storage costs through better data hygiene.
“What these outcomes show is that when data is treated not just as an infrastructure component but as an enabler of business velocity, the returns are both measurable and strategic,” Sengupta said.
{kind=link}
Top 6 multicloud management solutions 16 Jun 2025, 11:00 am
Multicloud is increasingly common in today’s enterprises. The use of multiple public clouds, even spreading applications across clouds, can help with compliance, boost availability, reduce risk, or avoid vendor lock-in. Companies also adopt multiple clouds to support best-of-breed strategies, or as the result of mergers or acquisitions.
Enterprises already use an average of 2.4 public cloud providers, according to Flexera’s 2025 State of the Cloud report. And multicloud adoption is anticipated to rise further, driven by new AI demands and the sovereign cloud movement. In addition to using multiple public clouds like Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), many enterprises today also rely on a mix of on-prem data centers, private clouds, bare-metal, and edge environments.
Multicloud management solutions help unify common functions across these environments, supporting deployment, configuration, governance, observability, monitoring, cost analysis, and more. No solution covers every area, though, which is why niche tools have emerged for deeper customization.
Below, we survey six top multicloud management systems for 2025. Some are cloud-provided, others cloud-agnostic. Some focus on infrastructure as code (IaC) or platform engineering, while others offer GUI-based control and enterprise bells and whistles. Some aim to provide all-purpose enterprise platforms, while others take a Kubernetes-first approach. Whatever your needs, the right fit is likely out there if you do some digging.
Google Cloud Anthos
Multicloud manager with hyperscaler muscle
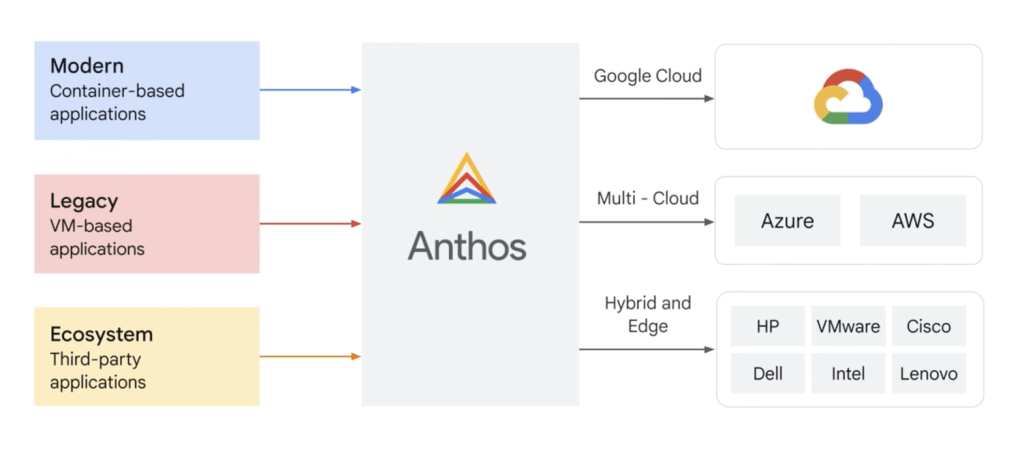
Google Cloud Anthos is a full-featured managed platform that enables you to build and manage Kubernetes-based container applications in hybrid cloud and multicloud environments. Don’t let the name fool you—Anthos works with AWS, Azure, and GCP, as well as workloads on premises and at the edge.
Anthos provides a single control plane with declarative policies to ensure consistency across configuration management, service mesh, security, access policies, telemetry, and observability. You can group “fleets” to organize clusters and resources for multicloud administration.
At its core are open source projects like Kubernetes, Istio, Knative, and Tekton. Anthos can run anywhere and includes tooling to aid VM-to-container migration. It also provides a marketplace for third-party add-ons.
One hindrance—for fans of vanilla Kubernetes—could be its bias toward Google’s flavor of Kubernetes under the hood (Google Kubernetes Engine, or GKE). But that’s a small gripe, considering Google created Kubernetes and continues to lead its development.
If you’re looking for a strong option to deploy, observe, monitor, and govern workloads on-premises and across major clouds—with the same power as GCP—then Anthos should be on your short list.
Google Cloud
HCP Terraform
Terraform with enterprise bells and whistles
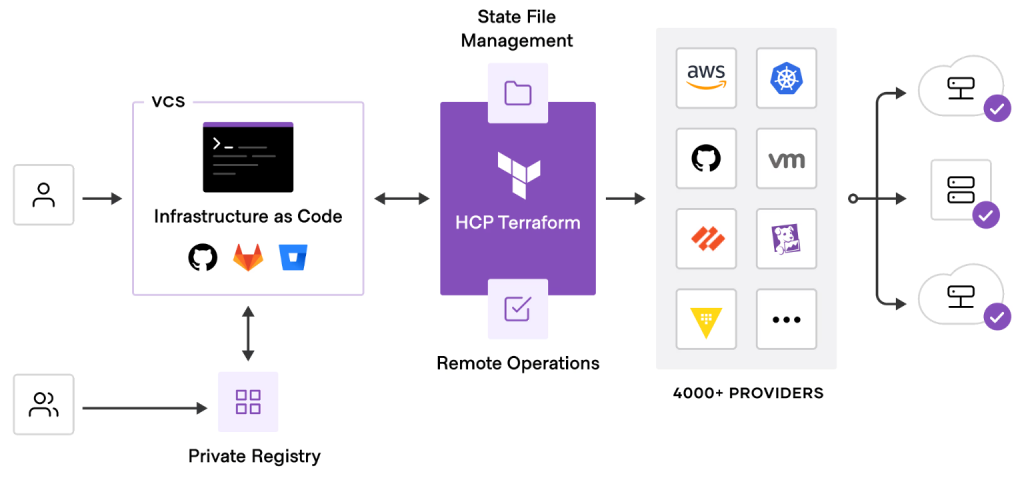
Terraform is a command-line tool and configuration language for infrastructure as code (IaC). Inherently multicloud, Terraform automates all kinds of provisioning and management tasks, covering everything from cloud server, storage, network, and database resources to deployment pipelines, serverless applications, Kubernetes clusters, and much more.
Built on top of Terraform, HashiCorp’s HCP Terraform offers a hosted platform to standardize and collaborate on IaC at scale. It abstracts configuration management with features like registries for modules and secrets, policy enforcement, state storage, and governance controls. A self-hosted option is also available.
Terraform itself is cloud-agnostic and supports AWS, Microsoft Azure, Google Cloud, Oracle Cloud, Alibaba Cloud, and more. It’s mature and widely adopted, having helped power the devops and container movements since 2014.
Once open source, Terraform is now licensed under HashiCorp’s Business Source License (BSL), prompting the creation of OpenTofu as a community-driven alternative—and the departure of some core maintainers. Another challenge is that writing and maintaining Terraform modules at scale can be complex, even with a managed platform.
That said, Terraform is the de facto cross-cloud IaC standard. If you don’t mind some lock-in, HCP Terraform offers granular control over cloud resources with SaaS-like usability.
HashiCorp
HPE Morpheus Enterprise
Hybrid multicloud with wide enterprise coverage
HPE Morpheus Enterprise is a hybrid multicloud management solution that stands out for its broad feature coverage and support for both visual and programmable infrastructure automation.
Morpheus supports AWS, Microsoft Azure, Google Cloud Platform, IBM Cloud, Oracle Cloud, Nutanix, KVM, Kubernetes, and other niche clouds and surrounding technologies. It enables self-service provisioning, backups, compliance checks, and more—accessible via API, command-line interface, or GUI.
As you might expect from HPE, Morpheus is more tuned to the governance side of the multicloud equation than others on this list, with cost analytics, policy enforcement, and automation all part of the mix. Morpheus offers deep visibility and strong role-based access controls, making it a good choice for regulated environments.
HPE Morpheus Enterprise provides a flexible way to build various platform stacks, and integrates with a wide range of enterprise-oriented tools and services. However, Morpheus is a bit opinionated and not as built on open source as other options.
Morpheus makes sense for enterprises seeking a flexible, all-in-one solution for managing a hybrid infrastructure spanning on-prem data centers, edge deployments, and multiple clouds.

HPE
Humanitec
Multicloud deployment shifts to the developer
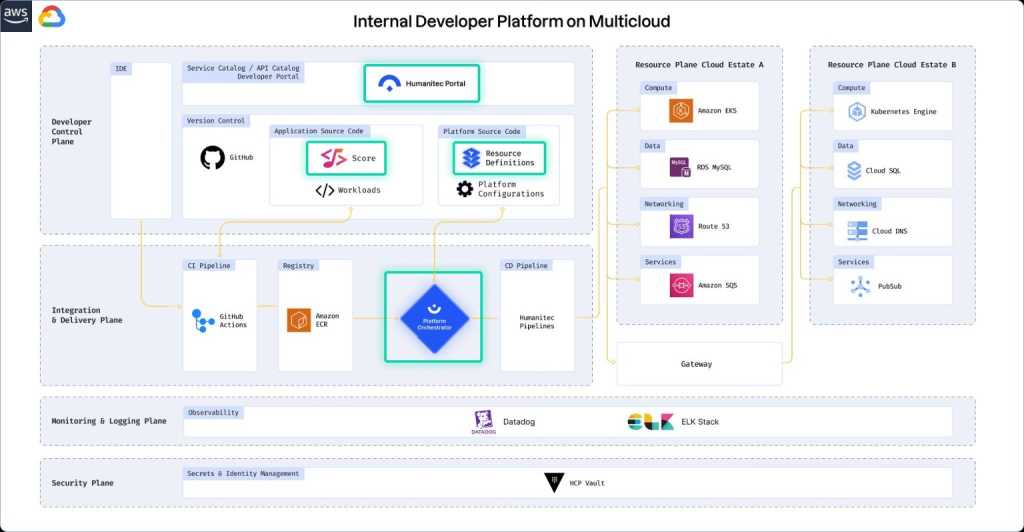
As platform engineering gains traction, internal developer platforms (IDPs) are reframing multicloud management, abstracting devops complexity and enabling self-service workflows. Humanitec leads this space, offering a cloud-agnostic infrastructure management layer.
Rather than prescribing tools, Humanitec serves as a “platform for platforms,” letting you stitch together your stack. Developers define workloads using Score, a workload spec, while the Platform Orchestrator generates configurations and populates a visual UI for deployment and management.
Humanitec is purpose-built for optimizing the cloud-native deployment-feedback loop, and it can be configured to work across all major clouds. But, it isn’t focused on cost visibility or legacy VM orchestration like traditional multicloud suites, and it doesn’t replace observability or security tools.
If your platform team wants to build a flexible, developer-friendly layer for cross-cloud deployments and operations, Humanitec is a strong choice. That said, it’s not alone—alternatives include Port, Crossplane, and Backstage, each offering different flavors of the IDP approach.
Humanitec
Nutanix Cloud Platform
A single pane of glass for hybrid multicloud
Nutanix is a hybrid multicloud platform that is quite universal—it can be used to run, manage, and secure virtual machines and containers across public clouds, private data centers, and edge environments.
Nutanix Cloud Platform consolidates functionality typically spread across multiple tools into a single control plane. It offers cost analysis, Kubernetes management, data security, monitoring, self-healing, disaster recovery, and more.
Nutanix Cloud Platform is highly tuned for deploying and migrating enterprise apps and databases across environments. You choose your hardware, hypervisor, cloud provider, and Kubernetes platform, and the Nutanix platform stitches it all together. It also includes automation to optimize performance and detect security anomalies across clouds.
Nutanix Cloud Platform is GUI-first and opinionated, emphasizing “click ops” over code. This can be a plus for IT teams without established IaC workflows, but may turn off devops engineers looking for code-based, declarative control.
If you need broad feature coverage in a platform that supports on-prem and multicloud, and you prefer a managed experience over heavy scripting, Nutanix is a strong choice.
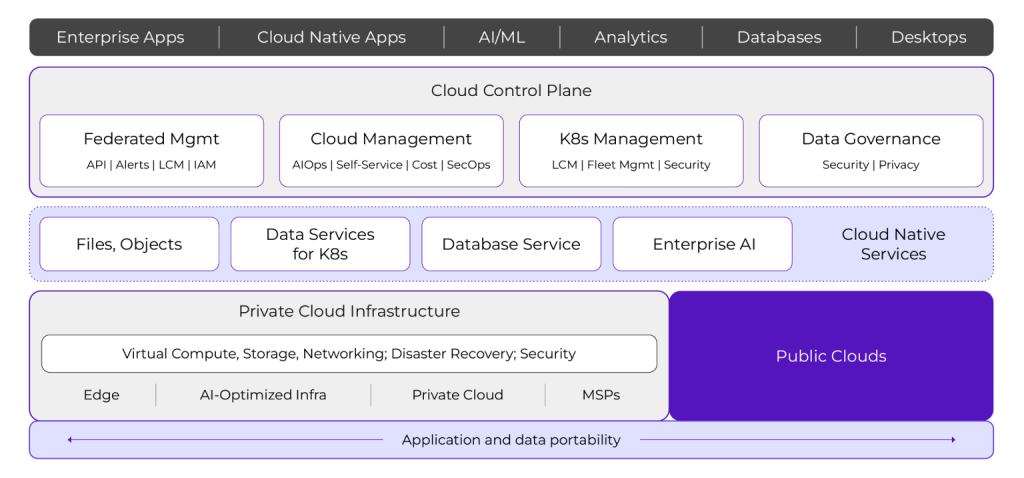
Nutanix
Palette
Kubernetes-first malleable multicloud operations
It didn’t take long for Kubernetes to become the cloud-agnostic container engine of choice in the enterprise. Palette, by Spectro Cloud, is a strong option for enterprises building on Kubernetes that require a multicloud management layer.
Palette provides a modular architecture for managing cluster operations across the stack, including deployment, security policies, networking, and monitoring. It supports all major clouds as well as bare metal, edge, and data center deployments, using a declarative model based on the Cloud Native Computing Foundation’s Cluster API (CAPI).
Spectro Cloud provides “packs,” a layered stack concept that supports a wide range of integrations for areas like authentication, ingress, edge Kubernetes, networking, security, service mesh, and more. This enables best-of-breed customization for specific needs.
While Spectro Cloud enforces configurations, policies, and life cycle constraints, deep governance and cost analysis are out of scope.
Palette is a great option for devops-heavy, Kubernetes-native organizations that span multiple clouds and need a malleable solution to unify operations and delivery across environments.
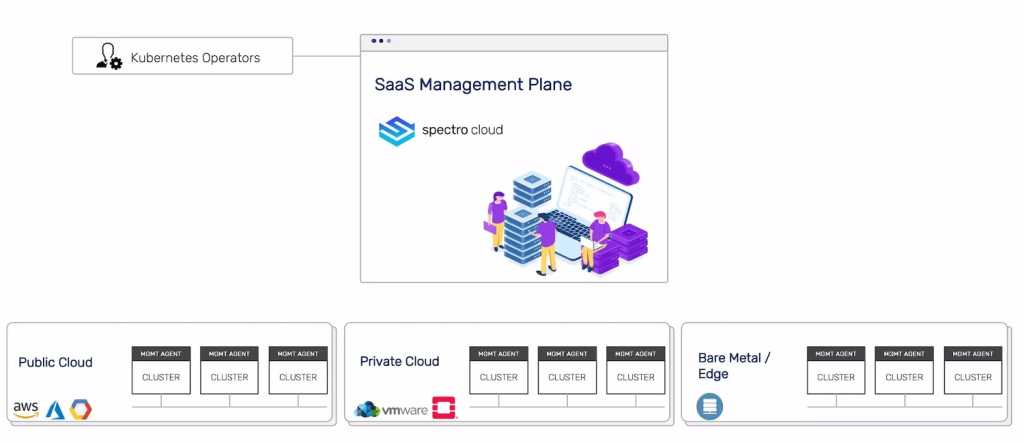
Spectro Cloud
Honorable mentions
There are a number of other platforms that get the broad multicloud sticker, because they work across clouds and have 80% of the expected features. SUSE Rancher and Cloudify are two other mature, all-in-one examples with proven industry use. Early-stage players aiming to orchestrate multicloud operations include Firefly, Fractal Cloud, and Emma.
Plenty of alternative Kubernetes platforms (like Platform9, Mirantis, and D2iQ) support public and private cloud deployments. For VMware-heavy organizations, VMware Cloud Foundation (VCF) from Broadcom offers a platform to manage VMware-based workloads across private and VMware-aligned public cloud environments.
And there are plenty of niche tools to fill the gaps. As we’ve seen, many multicloud management platforms focus on deployment and configuration, leaving out functions like cost analysis and policy enforcement. These specialized tools cover those gaps and others:
- Cost analysis and optimization: Flexera Cloud Management Platform, Cloudbolt, CloudHealth by VMware, CloudZero, Apptio Cloudability, OpenCost, and Kion
- Deployment and GitOps: ArgoCD, Spacelift, Harness, Red Hat Ansible, and Scalr
- Policy, governance, and security: Open Policy Agent (OPA), Fugue, Prisma Cloud, and Lacework
- Monitoring and observability: Datadog, New Relic, Grafana Cloud, and Dynatrace
A moving target
73% of organizations are using two or more clouds, according to a 2025 survey of 500 IT leaders by HostingAdvice.com. Yet, while multicloud is now commonplace, true multicloud management is more elusive. Each cloud has its own nuances, making a truly agnostic, fully-featured control plane for deploying and managing workloads a dream we’re still chasing.
Because the industry keeps swinging between monolithic “all-in-one” platforms and best-of-breed microservices for niche tasks, it’s hard to decipher where cloud management approaches will ultimately land. It’s also increasingly iffy to recommend open-source options as a sure thing, given ongoing license changes and ecosystem fragmentation.
Thankfully, the platforms discussed above can take you a good way toward multicloud usage, abstracting much of the complexity and offering unified control plane options for your estates. Of course, this comes with tradeoffs—namely, vendor lock-in and giving up some control over building your own platform. That’s one reason platform engineering has emerged as a key practice.
Looking ahead, cloud-agnostic layers to manage these experiences will remain essential—and they’ll continue to evolve with each new technology wave.
{kind=link}
Rethinking the dividing lines between containers and VMs 16 Jun 2025, 11:00 am
The technology industry loves to redraw boundary lines with new abstractions, then proclaim that prior approaches are obsolete. It happens in every major arena: application architectures (monoliths vs. microservices), programming languages (JVM languages vs. Swift, Rust, Go), cloud infrastructure (public cloud vs. on-prem), you name it.
False dichotomies are good at getting people excited and drawing attention, and they make for interesting debates on Reddit. But nearly without exception, what tends to happen in tech is a long period of co-existence between the new and the old. Then usually the old gets presented as new again. Monolithic application architectures sometimes prevail despite modern theology around microservices. On-prem data centers have not, in fact, been extinguished by public clouds. Serverless has not killed devops. The list goes on.
I think the most interesting false dichotomy today is the supposed line between virtual machines (VMs) and containers. The former has been maligned (sometimes fairly, sometimes not) as expensive, bloated, and controlled by a single vendor, while the latter is generally proclaimed to be the de facto application format for cloud-native deployments.
But the reality is the two worlds are coming closer together by the day.
Now more than 10 years into the rise of containers, the relationship between containers and VMs can be better described in terms of melding, rather than replacement. It’s one of the more nuanced evolutionary themes in enterprise architecture, touching infrastructure, applications, and, most of all, security.
The rise of containers
The lineage of containers and virtual machines is rather involved. Linux namespaces, the primitive kernel components that make up containers, began in 2006. The Linux Containers project (LXC) dates back to 2008. Linux-vserver, an operating system virtualization project similar to containers, began in 1999. Virtuozzo, another container tech for Linux that uses a custom Linux kernel, was released as a commercial product in 2000 and was open-sourced as OpenVZ in 2005. So, containers actually predate the rise of virtualization in the 2000’s.
But for most of the market, containers officially hit the radar in 2013 with the introduction of Docker, and started mainstreaming with Docker 1.0 in 2015. The widespread adoption of Docker in the 2010’s was a revolution for developers and set the stage for what’s now called cloud-native development. Docker’s hermetic application environment solved the longstanding industry meme of “it works on my machine” and replaced heavy and mutable development tools like Vagrant with the immutable patterns of Dockerfiles and container images. This shift enabled a new renaissance in application development, deployment, and continuous integration (CI) systems. Of course, it also ushered in the era of cloud-native application architecture, which has experienced mass adoption and has become the default cloud architecture.
The container format was the right tech at the right time—bringing so much agility to developers. Virtual machines by comparison looked expensive, heavyweight, cumbersome to work with, and—most damning—were thought of something you had to wait on “IT” to provision, at a time when the public clouds made it possible for developers to simply grab their own infrastructure without going through a centralized IT model.
The virtues of virtual machines
When containers were first introduced to the masses, most virtual machines were packaged up as appliances. The consumption model was generally heavyweight VMware stacks, requiring dedicated VM hosts. Licensing on that model was (and still is) very expensive. Today, when most people hear the term “virtualization,” they automatically think of heavyweight stacks with startup latency, non-portability, and resource inefficiency. If you think of a container as a small laptop, a virtual machine is like a 1,000 pound server.
However, virtual machines have some very nice properties. Over time there’s been interest in micro-VMs, and a general trend toward VMs getting smaller and more efficient. The technology in the Linux kernel has evolved to the point where you can reasonably run a customer application in a separate kernel. These evolutionary gains have made VMs much more friendly as a platform, and today virtual machines are all around us.
On Windows, for example, if you install on normal hardware, you are running on virtual machines for security purposes. It has become commonly accepted that hypervisors are a powerful way to do security. Containers running in virtual machines can run on any cloud environment, and no longer just the private environment of the hypervisor providers.
Containers and VMs join forces
The need for multi-tenancy and the lack of a good security isolation boundary for containers are the primary reasons why containers and virtual machines are coming together today.
Containers don’t actually contain. If you’re running multiple workloads and apps inside a Kubernetes cluster, they’re all sharing the same OS kernel. So should a compromise happen to one of those containers, it could be a bad day for every other container plus the infrastructure that runs them.
Containers by default provide an OS-level virtualization that provides a different view of the file system and processes, but if there are any exploits in the Linux kernel, you can then pivot to the entire system, get privilege escalation, and either escape the container or execute processes in a process or context you shouldn’t be allowed to.
So, one of the fundamental reasons why the container and virtual machine worlds are colliding is that virtualized containers (aka, “virtual machine containers”) allow each container to run in its own kernel, with separate address spaces that do not touch the same Linux kernel the host system uses.
While security isolation in multi-tenant environments is the “hair on fire” reason why virtual machine containers are on the rise, there are also broad economic reasons challenging the boundaries between virtual machines and containers. When you have a virtual machine, you can assign specific memory requirements or specific CPU limitations in a more granular way and even apply usage policies at a global level.
Introducing Krata
The container format is a nearly 20-year-old evolution in how modern applications are created and operated across distributed cloud infrastructure. Although virtual machines were supposed to wither as the world adopted containers, the reality is that VMs are here to stay. Not only do virtual machines still have a large installed base, but developers are drawing on VM design principles to address some of containers’ still-turbulent challenges.
Krata, an open-source project by Edera, pairs a Type 1 hypervisor (the Xen microkernel) with a control plane that has been reimagined and rewritten in Rust to be container native. Krata provides the strong isolation and granular resource controls of virtual machines while supporting the developer ergonomics of Docker. It also creates an OCI-compatible container runtime on Kubernetes. This means Krata doesn’t require KubeVirt for virtualization; the system firmware boots and hands off to the Xen microkernel, which sets up interrupts and memory management for virtual machines that run pods in Kubernetes.
Because Krata uses a microkernel, it doesn’t make any changes to your existing Kubernetes operating system. You can use any OS—AL2023, Ubuntu, Talos Linux, etc.—and you don’t need KubeVirt to handle virtualization. Your containers run side-by-side on Kubernetes with no shared kernel state, preventing data access between workloads even in the event of kernel vulnerabilities.
Containers give developers flexibility, speed, and simpler deployment. Virtual machines offer superior workload isolation and security. For years, developers have been forced to choose. That’s changing.
Alex Zenla is co-founder and CTO of Edera.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
{kind=link}
SmartBear unveils AI-driven test automation for iOS and Android apps 13 Jun 2025, 11:49 pm
SmartBear has launched Reflect Mobile, an AI-powered, no-code, test automation tool kit that enables QA professionals to test native apps across the iOS and Android mobile platforms.
Announced June 11, Reflect Mobile features SmartBear’s HaloAI AI technology and extends SmartBear’s Reflect test automation solution, which was originally focused on web apps, to native mobile apps, SmartBear said. Reflect Mobile uses generative AI and record-and-replay to make test creation intuitive, fast, and codeless, according to the company. Reflect Mobile supports frameworks such as Flutter and React Native, enabling cross-platform testing via a single solution.
With Reflect Mobile, SmartBear advances its SmartBear Test Hub strategy, which brings API, web, and mobile testing into a unified solution, and helps teams simplify the testing of apps. Non-technical testers can build and maintain mobile test automation without needing scripting skills or engineering support. Built-in integrations for test management, device grid providers, and CI/CD pipelines enable Reflect Mobile to fit into existing QA and development environments, SmartBear said.
With the introduction of Reflect Mobile, SmartBear is marking a strategic expansion into the growing mobile-first market. SmartBear acquired Reflect in early-2024. Since then, SmartBear has integrated Reflect natural language test creation, visible insight capabilities, and AI automation into its suite of test automation solutions.
{kind=link}
Visual Studio Code bolsters MCP support 13 Jun 2025, 10:58 pm
Visual Studio Code 1.101, aka the May 2025 version of Microsoft’s popular code editor, expands support for the Model Context Protocol, a technology that standardizes how applications provide context to large language models.
VS Code 1.101 was released June 12. Downloads are available for Windows, Mac, and Linux.
With the new release, VS Code has expanded its support for MCP-enabled agent coding capabilities with support for prompts, resources, sampling, and authenticating with MCP servers. Prompts, which can be defined by MCP servers to generate reusable snippets or tasks for the language model, are accessible as slash commands in chat. Developers can enter plain text or include command output in prompt variables.
With VS Code’s MCP resource support, which includes support for resource templates, resources returned from MCP tool calls become available to the model, can be saved in chat, and can be attached as context via the Add Context button in chat. Developers can browse resources across MCP servers, or for a specific server, by using the MCP: Browse Resources command, or using the MCP: List Servers command.
VS Code 1.101 offers experimental support for sampling, which allows MCP servers to make requests back to the model, and now supports MCP servers that require authentication, enabling interaction with an MCP server that operates on behalf of a user account for that service. Developers now can enable development mode to debug MCP servers by adding a dev key to the server config.
Finally, new MCP extension APIs enable extensions to publish collections of MCP servers. This means VS Code extension authors can bundle MCP servers with their extensions or build extensions that dynamically discover MCP servers from other sources.
Other new features and improvements in VS Code 1.101:
- Developers now can define tool sets to use in chat, either through a proposed API or through the UI. Tool sets make it easier to group related tools together, and quickly enable or disable them in agent mode, Microsoft said.
- Selecting a history item in the Source Control Graph now reveals the resource for that item. Developers can choose between a tree view or list view representation from the
...menu. - Language server completions now are available in the terminal for interactive Python REPL sessions.
- Task
runoptionsnow has anInstancePolicyproperty that determines what happens when a task reaches itsInstancelimit.
{kind=link}
GitHub launches Remote MCP server in public preview to power AI-driven developer workflows 13 Jun 2025, 3:48 pm
GitHub has unveiled its Remote MCP server in public preview, allowing developers to integrate AI assistants like GitHub Copilot into their workflows without setting up local servers.
With just a click in Visual Studio Code or a URL in MCP-compatible hosts, coders can access live GitHub data — including issues, pull requests, and code — in real time, GitHub said in a blog post.
Unlike its local counterpart, the remote server is hosted by GitHub but retains the same codebase. It supports secure OAuth 2.0 authentication with Personal Access Tokens as a fallback, making adoption easier while maintaining control.
“This shift gives enterprises backend flexibility while preserving the familiar Codespaces UI,” said Nikhilesh Naik, associate director at QKS Group. “It decouples the orchestration control plane from GitHub’s infrastructure, a key step for hybrid developer setups.”
The technology builds on the Model Context Protocol, or MCP, which Keith Guttridge, VP Analyst at Gartner, described as “an emerging but crucial standard for AI tool interoperability.” While currently focused on developer experience, Guttridge noted MCP is evolving rapidly, with enterprise-grade features such as registry support and enhanced governance on the roadmap.
MCP’s growth mirrors broader industry demands, said Dhiraj Pramod Badgujar, senior research manager at IDC Asia/Pacific. “Self-hosted remote execution aligns with hybrid DevOps trends, balancing speed with security, especially for compliance-driven workflows.”
Hybrid workflows and enterprise flexibility
The Remote MCP server is designed to meet enterprise needs for hybrid development environments, particularly in sectors with strict compliance or network rules.
“GitHub’s shift to externalize the Remote MCP server is a technically deliberate response to enterprise demands for hybrid developer infrastructure,” Naik said, “where development workflows must align with internal network boundaries, compliance constraints, and infrastructure policies.”
The server allows enterprises to run development containers on self-managed Kubernetes clusters or virtual machines, integrating seamlessly with internal DNS, secret management, and CI/CD pipelines, positioning GitHub as a modular layer for internal developer platforms.
For industries handling sensitive intellectual property, the server aligns with GitHub’s existing policy framework. Guttridge said it “simplifies the process of enabling AI tools to interact with GitHub Services” without changing protections for regulated sectors.
Badgujar noted that enterprises prioritize internal control to strengthen security and manage cloud costs. “This supports DevSecOps by standardizing environments and aligning DevSecOps with governance policies,” he said.
The server currently requires the Editor Preview Policy for Copilot in VS Code and Visual Studio. It does not support JetBrains, Xcode, and Eclipse IDEs, which still rely on local MCP servers.
GitHub’s ecosystem advantage
Compared to competitors, GitHub’s remote MCP server leverages its ecosystem strengths. Naik argued that it shares GitHub Coder’s self-hosting capabilities but integrates more tightly with GitHub’s repositories and Codespaces containers for consistent environments, while Gitpod offers greater platform-agnostic flexibility.
Badgujar said GitHub balances execution and uniformity across Actions and Codespaces, unlike GitLab’s full-stack DevSecOps approach or Atlassian’s cloud-first focus.
Toward modular, secure development
Self-hosting the Remote MCP server reduces exposure to external systems but increases internal responsibilities.
“Though running in-house developer environments reduces external risk,” Naik said. “ But it pushes a lot of responsibility onto internal teams.”
Misconfigured permissions or weak container isolation could expose vulnerabilities, requiring robust sandboxing, audit trails, and secure integration with tools like artifact repositories and secret stores.
Guttridge cautioned that MCP, while promising, is still maturing. “It needs to evolve towards a more enterprise-ready standard with regard to registry, discovery, and governance,” he said, urging careful adoption in trusted environments.
Still, the architecture paves the way for modular, cloud-agnostic platforms. By decoupling the Codespaces frontend from backend orchestration, it enables workspaces to run across cloud VMs, bare-metal clusters, or edge nodes.
“This fosters API-driven, stateless environments with components like language servers and debuggers,” Naik said. Badgujar echoed that view, adding: “MCP has the potential to become the de facto standard of connecting AI-enabled systems together as it matures, helping reduce vendor lock-in.”
The GitHub MCP server repository is now available for developers to test during the preview period. While early in development, the Remote MCP Server marks a significant step toward modular, AI-powered developer platforms.
{kind=link}
New Python projects to watch and try 13 Jun 2025, 11:00 am
Get a first look at the new Python Installation Manager for Windows, or try your hand at developing AI agents with Google’s Agent Development Kit for Python, or check out template strings in Python 3.14. Would you rather debate virtual threads in Python, or catch up on the May 2025 Python Language Summit? We’ve got that, too. It’s all here (and more) in this week’s Python Report.
Top picks for Python readers on InfoWorld
Get started with the new Python Installation Manager
At last, we have a native Python tool for installing, removing, and upgrading editions of the language in Microsoft Windows! It’s still in beta, but Python Installation Manager is set to replace py before long. Why not give it a spin now?
How to deploy AI agents with the Google Agent Development Kit for Python
Google’s newly released toolkit for Python (and Java) eases you into writing complex, multi-step AI agents. And it doesn’t matter whether you’re using Google’s AI or someone else’s.
Python 3.14’s new template string feature
Once upon a time, there were f-strings for formatting variables in Python, and they were good … mostly. Now Python 3.14 introduces t-strings, or “template strings,” for a range of variable-formatting superpowers that f-strings can’t match.
How to use Marimo, a better Jupyter-like notebook system for Python
Jupyter Notebooks may be a familiar and powerful tool for data science, but its shortcomings can be irksome. Marimo offers a Jupyter-like experience, but it’s more convenient, interactive, and deployable.
More good reads and Python updates elsewhere
NumPy 2.3 adds OpenMP support
Everyone’s favorite Python matrix math library now supports OpenMP parallelization, although you’ll have to compile NumPy with the -Denable_openmp=true flag to use it. This is the first of many more future changes to NumPy adding support for free-threaded Python.
Pyfuze: Package Python apps into single executables
This clever project uses uv to conveniently deliver Python apps with all their dependencies included in a single redistributable package. You can even download and install the needed bits at setup time for a smaller initial package.
Does Python need virtual threads?
Python’s core developers are deciding now whether to add this Java-esque threading feature to Python. Do we need yet another concurrency feature on top of regular threads, async, multiprocessing, and subinterpreters in Python? You decide.
The Python Language Summit 2025
When Python’s best and brightest gathered in Pittsburgh this past May, they spoke of many things. This collection of blog posts offers a recap of topics such as fearless concurrency, the state of free-threaded Python, Python on mobile devices, and more.
{kind=link}
Europe is caught in a cloud dilemma 13 Jun 2025, 11:00 am
Europe stands at a crucial crossroads as it navigates two significant influences: the European Union’s desire for digital independence from foreign cloud providers and its desire for access to state-of-the-art cloud technologies. Certain foreign hyperscalers, particularly those based in the United States, provide advanced cloud products and services that European hyperscalers cannot yet match.
It’s never ideal to give foreign entities access to key components of a business. However, many companies want to take advantage of the benefits offered by non-native cloud providers without the potential restrictions imposed by foreign governments on the global distribution and use of those products and services. The situation in Europe may not have a straightforward solution. It requires strategic cloud utilization with improved architectural design considerations.
Keep your data close
The European Union is worried about its reliance on the leading US-based cloud providers: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). These large-scale players hold an unrivaled influence over the cloud sector and manage vital infrastructure essential for driving economies and fostering innovation. European policymakers have raised concerns that their heavy dependence exposes the continent to vulnerabilities, constraints, and geopolitical uncertainties.
In one example, potential access to US company data storage under laws such as the US CLOUD (Clarifying Lawful Overseas Use of Data) Act has sparked concerns among experts worldwide. Additionally, recent US government decisions have demonstrated how swiftly government actions can impact markets. These concerns have prompted efforts such as Gaia-X, a European initiative promoting cooperation and developing options to reduce reliance on the US cloud industry.
The fundamental objective is clear: The EU seeks greater control over its digital framework.
The truth about cloud innovation
What exacerbates the situation in Europe is that tech giants in the United States dominate the market for a reason. Their services are the result of research and development efforts coupled with massive financial investments over the years. Their large scale allows them to offer technologies such as AI-driven data analysis tools and serverless computing solutions at prices smaller companies struggle to compete with.
Europe currently lacks cloud service providers that can challenge those global Goliaths. Despite efforts like Gaia-X that aim to change this, it’s not clear if Europe can catch up anytime soon. It will be a prohibitively expensive undertaking to build large-scale cloud infrastructure in Europe that is both cost-efficient and competitive. In a nutshell, Europe’s hope to adopt top-notch cloud technology without the countries that currently dominate the industry is impractical, considering current market conditions.
Best of both worlds
For now, Europe should adopt a more nuanced approach instead of an extreme strategy regarding cloud usage on a business scale. The key is to reconsider how cloud services are utilized by combining US and European options to enhance performance efficiency while cutting costs and reducing reliance on overseas companies.
Hybrid and multicloud setups are crucial to finding the equilibrium. Businesses can customize their IT landscape by distributing tasks across multiple cloud platforms to meet their specific requirements. For instance, critical data and applications can be hosted by local providers, whereas AI or cutting-edge analytics can benefit from hyperscale platforms.
This goes beyond a short-term fix. It’s a thoughtful approach to maintaining independence while still embracing innovation. Companies in Europe can create plans that combine the advantages of different systems, reducing their reliance on a single provider and promoting greater compatibility.
This method requires businesses and organizations to assess their use of cloud services and accurately determine their key workload needs and challenges before transitioning to a hybrid cloud setup, which mixes services from different providers.
A comprehensive strategy
The essence of this approach is design strategy. Often companies view cloud integration as merely a checklist or set of choices to finalize their cloud migration. This frequently results in tangled networks and isolated silos. Instead, businesses should overhaul their existing cloud environment with a comprehensive strategy that considers both immediate needs and future goals as well as the broader geopolitical landscape.
Utilizing a range of necessary cloud services, everything from major cloud providers to specialized local and international ones, requires seamless data integration and compatibility between systems. A well-designed cloud architecture not only helps minimize potential risks but also positions a company to foster innovation and expansion.
The long view
The European Union’s goals for independence are reasonable. They require a careful balance of autonomy in cloud computing without sacrificing access to cutting-edge technologies, at least in the near to mid-term future.
The EU must navigate ambition and practicality. It is crucial not to compel everyone to use only local cloud services or create barriers against foreign companies, which could harm competition and suppress innovation. Policies that restrict options based on location should aim to boost overall usage while supporting European advancements in specialized fields, such as quantum computing and advanced chip production.
The European Union faces a multifaceted challenge of integrating sovereignty and innovation without excluding either aspect entirely or relying too heavily on untested European options. Rather than dismissing large-scale cloud services or prematurely committing to untried European solutions, the EU should adopt a diverse cloud strategy that prioritizes performance optimization, risk management, and sustainable growth over time. In the pursuit of competitiveness, Europe’s most significant opportunity lies in developing an interconnected architectural framework rather than fostering division.
{kind=link}
.NET 10 Preview 5 highlights C# 14, runtime improvements 12 Jun 2025, 9:50 pm
Microsoft has launched the fifth preview of its planned .NET 10 open source developer platform. The preview release fits C# 14 with user-defined compound assignment operators and enhances the .NET runtime with escape analysis, among other updates.
Announced June 10, .NET 10 Preview 5 can be downloaded from dotnet.microsoft.com. It includes enhancements to features ranging from the runtime and C# 14 to F# 10, NET MAUI, ASP.NET Core, and Blazor.
C# 14 type authors can now implement compound assignment operators in a user-defined manner that modifies the target in place rather than creating copies. Pre-existing code is unchanged and works the same as before. Meanwhile, in the .NET runtime, the JIT compiler’s escape analysis implementation has been extended to model delegate invokes. When compiling source code to IL (intermediate language), each delegate is transformed into a closure class with a method corresponding to the delegate’s definition and fields matching any captured variables. At runtime, a closure object is created to instantiate the captured variables along with a Func object to invoke the delegate. This runtime preview also enhances the JIT’s inlining policy to take better advantage of profile data. Additionally, F# 10 introduces scoped warning controls with a new #warnon directive supporting fine-grained control over compiler diagnostics.
A production release of .NET 10 is expected this November. .NET 10 Preview 5 follows Preview 4, announced May 13. The first preview was unveiled February 25, followed by a second preview on March 18, and the third preview, announced April 10. Other improvements featured in Preview 5 include:
- For ASP.NET Core, developers now can specify a custom security descriptor for
HTTP.sysrequest queues using a newRequestQueueSecurityDescriptorproperty onHttpSysOptions. This enables more granular control over access rights for the request queue, allowing developers to tailor security to an application’s needs. - The OpenAPI.NET library used in ASP.NET Core OpenAPI document generation has been upgraded to v2.0.0-preview18.
- Blazor now provides an improved way to display a “not Found” page when navigating to a non-existent page. Developers can specify a page to render when
NavigationManager.NotFound()is called by passing a page type to theRoutercomponent using theNotFoundPageparameter. - For .NET MAUI, projects now can combine XML namespaces into a new global namespace,
xmlns="http://schemas.microsoft.com/dotnet/maui/global", and use these without prefixes. - For Windows Presentation Foundation, the release introduces a shorthand syntax for defining
Grid.RowDefinitionsandGrid.ColumnDefinitionsin XAML, with support for XAML Hot Reload. Performance and code quality are also improved.
{kind=link}
Databricks One mirrors Microsoft Copilot strategy to transform enterprise data access 12 Jun 2025, 1:28 pm
Databricks has previewed a no-code version of its Data Intelligence platform — Databricks One — that aims to provide AI and BI tools to non-technical users through a conversational user interface.
According to analysts, Databricks One draws inspiration from Microsoft’s M365 Copilot strategy to reimagine the user interface of M365, centering on generative AI, and applies this approach to the enterprise data analytics tools that Databricks provides.
“Databricks One mirrors Microsoft’s M365-Copilot strategy in that it reimagines the user interface, although not for productivity apps, but for enterprise data and AI,” said Michael Ni, principal analyst at Constellation Research.
Speaking to Computerworld, last month, a top Microsoft executive said that the company was planning to move away from a typical apps based interface to a Copilot driven experience in the future: instead of accessing individual apps like Word, Excel and PowerPoint, users prompts Copilot with the task at hand and the generative AI assistant spins up the required application.
Databricks One similarly offers a simplified, AI-assisted access point to governed data, metrics, and insights, helping business teams engage without code or complexity.
“It’s not about replacing business intelligence (BI) tools, but about embedding decision intelligence into daily workflows,” Ni said.
One comes with AI/BI Dashboards and apps
As part of the One platform, which is currently in private preview and can be accessed by Data Intelligence platform subscribers for free, Databricks is offering AI/BI Dashboards, Genie, and Databricks Apps along with built-in governance and security features via Unity Catalog and the Databricks IAM platform.
While AI/BI Dashboards will enable non-technical enterprise users to create and access data visualizations and perform advanced analytics without writing code, Genie, a conversational assistant, will allow users to ask questions on their data using natural language.
The conversational assistant is also expected to support deep research on data as it understands business-specific semantics, the company said.
Additionally, Databricks Apps inside One will allow non-technical users to package complex workflows that interweave analytics, AI, and transactional processing in a custom app for a particular use case, the company said.
However, Moor Insights and Strategy principal analyst Robert Kramer pointed out that enterprises shouldn’t expect every advanced feature of the Data Intelligence platform to be baked inside One, despite it connecting to the same backend core engine of the platform and working on the same enterprise data.
Centralizing metadata on Databricks’ platform
Analysts see Databricks One as a vehicle for the lakehouse provider to drive stickiness of its products.
“Databricks One is a Trojan horse for garnering enterprise mindshare and an effort towards centralizing metadata on Databricks’ platform. The more users rely on One to make decisions, the more sticky the Databricks platform becomes,” said Constellation Research’s Ni.
The decision to launch One could be seen as Databricks’ first salvo in the next war engulfing the data and analytics space: It isn’t just about which vendor has captured more enterprise data, but which vendor helps enterprises understand it better and makes it easy to use for business scenarios or use cases, Ni added.
Although, when compared to rivals, Databricks’ approach to making analytics easier without code and accessible via natural language is not new, Kramer pointed out that Databricks One stands out.
“Other vendors like Snowflake (with Cortex AI) and Microsoft (with Fabric and Copilot) also offer natural language tools for business users. Databricks One stands out because it’s built directly into the lakehouse platform,” Kramer said. Separately, Databricks has also launched a free edition of its Data Intelligence platform in order to encourage users to try out the gamut of tools and capabilities that the platform offers.
Analysts see the free edition as a “classic category capture.”
While at one end it will help shape the talent ecosystem when it comes to Databricks’ stack, it is also a moat builder at the other end, Ni said, adding that the earlier developers and data analysts get hooked into Databricks, the harder it is for rivals to pry them loose later.
However, Kramer pointed out that the free edition only includes basic computing resources while placing limits on how many jobs or apps a user can run.
“It doesn’t include enterprise features like advanced security or large-scale storage,” Kramer said.
Databricks has not provided any information on the usage limitations of the free editions.
In contrast, rivals such as Snowflake offer free trials that usually expire after a set time, often 30 days.
More DataBricks news:
{kind=link}
Use geospatial data in Azure with Planetary Computer Pro 12 Jun 2025, 11:00 am
Among his many achievements, pioneering computer scientist and Microsoft Technical Fellow Jim Gray came up with what he called the “fifth paradigm” of science: using large amounts of data and machine learning to discover new things about the world around us. That idea led to Microsoft’s work with scientists across the planet through its AI for Earth and similar projects.
Part of that work led to the development of a common source of geospatial data for use in research projects. Dubbed the Planetary Computer, the project built on a set of open standards and open source tools to deliver a wide variety of different geographic and environmental data sets that can be built into scientific computing applications. There are more than 50 petabytes of geospatial data in 120 data sets.
Adding geospatial data to scientific computing
Open the Planetary Computer data catalog and you will find all kinds of useful data: from decades’ worth of satellite imagery to biomass maps, from the US Census to fire data. All together, there are 17 different classes of data available, often with several different sources, all ready for research applications, on their own or to provide valuable context to your own data. A related GitHub repository provides the necessary code to implement much of it yourself.
Along with the data, the research platform includes a tool to quickly render data sets onto a map, giving you a quick way to start exploring data. It also provides the necessary Python code to include the data in your own applications. For example, you could mix demographic information with terrain data to show how population is affected by physical geography.
Data like this can help quickly prove or disprove hypotheses. This makes it a valuable tool for science, but what if you want to use it alongside the information stored in your own business systems?
From the lab to the enterprise
At Build 2025, Microsoft announced a preview of a new enterprise-focused version of this service, called Planetary Computer Pro. It’s wrapped as an Azure service and suitable for use across your applications or as part of machine learning services. The service can be managed using familiar Azure tools, including the portal and CLI, as well as with its own SDK and APIs.
Like the academic service, Planetary Computer Pro builds on the open SpatioTemporal Asset Catalog (STAC) specification, which allows you to use a standard set of queries across different data sets to simplify query development. It provides tools for visualizing data and supports access controls using Entra ID and Azure RBAC. It’s for your own data; it doesn’t provide third-party data sets for now, though direct links to the Planetary Computer service are on the road map, and the examples in Microsoft Learn show how to migrate data between the services.
Building a geospatial computing environment on top of Azure makes a lot of sense. Underneath Azure, tools like Cosmos DB and Fabric provide the necessary at-scale data platform, and support for Python and the Azure AI Foundry allow you to build analytical applications and machine learning tools that can mix geospatial and other data—especially time-series data from Internet of Things hardware and other sensors.
Planetary Computer Pro provides the necessary storage, management, and visualization tools to support your own geospatial data in 2D and 3D, with support for the necessary query tools. A built-in Explorer can help show your data on a map, letting you layer different data sets and find insights that may have been missed by conventional queries.
Microsoft envisions three types of user for the service. First are solution developers who want a tool for building and running geospatial data-processing pipelines and hosting applications using that data. The second group is data managers who need catalog tools to control and share data and provide access to developers across the enterprise. Finally, data scientists can use its visualization tools to explore geospatial data for insights.
Building your own geospatial catalog
Getting started with Planetary Computer Pro requires deploying a GeoCatalog resource into your Azure tenant. This is where you’ll store and manage geospatial data, using STAC to access data. You can use the Azure Portal or a REST API to create the catalog. While the service is in preview, you’re limited to a small number of regions and can only create publicly accessible catalogs. Deployment won’t take long, and once it’s in place you can add collections of data.
With a GeoCatalog in place you can now start to use the Planetary Computer Pro web UI. This is where you create and manage collections, defining data sources and how they’re loaded. It includes an Explorer view based on the one in Planetary Computer, which takes STAC data and displays it on a map.
You need to understand STAC to use Planetary Computer Pro, as much of the data used to define new collections needs to be written in STAC JSON. This can be uploaded from a development PC or authored inside the web UI. You can use Planetary Computer Pro’s own templates to simplify the process.
Data can now be brought into your collection. Data needs to be stored in Azure Blob Storage Containers; once it’s in place, all you need to do is provide the storage URI to Planetary Computer Pro. Azure’s identity management tool allows you to ensure only authenticated accounts can import data.
Importing data into a catalog
Imports use Python to copy data into a collection, using the STAC libraries from pip. This allows you to add metadata to images, along with data about the source, the time the data was collected, and the associated coordinates, for example, a bounding box around an image or precise coordinates for a specific sensor. There’s a lot of specialized information associated with a STAC record, and this can be added as necessary, allowing you to provide critical information about the data you’re cataloging. It’s important to understand that you’re building a catalog, akin to one in a library, not a database.
The STAC data you create can be used to find the data you need and then align it appropriately on a map, ready for use. That data can then be used alongside traditional queries for, say, time-series data to show how weather and geographic relief affect a vineyard’s yield.
If you have a lot of data to add to a catalog, you can use the service’s bulk ingestion API to add it to a collection. All the data needs to be in the same Blob Container, with code to provide the STAC data for each catalog entry based on your source’s metadata. The built-in Explorer helps you validate data on maps.
With data stored in a catalog, you can now use the Planetary Computer Pro APIs to start using it your own applications, with tools for searching STAC data, as well as tiling images onto maps ready for display. You can even link it to geographic information systems like ESRI’s ArcGIS, Microsoft’s own Fabric data lakes, or the Azure AI Foundry as part of machine learning applications.
Building a geographic Internet of Things
How can you use Planetary Computer Pro? One use case is to provide added context for machine learning systems or teams using Fabric’s new Digital Twin feature. Large-scale energy production systems are part of much larger environmental systems, and Planetary Computer Pro can provide more inputs as well as visualization tools. Having geospatial data alongside the sensor data adds other prediction options.
Planetary Computer Pro also fits in well with Microsoft’s work in precision agriculture, adding tools for better weather prediction features and a deeper understanding of how a local ecosystem has developed over time using historical satellite imaging data to track biodiversity and growth patterns. You can even use your own drones and aerial photography to add geospatial data to applications, comparing your current growth and yield with historical regional data.
Too often we think of the systems we’re building and modeling as isolated from the planet they’re part of. We are learning otherwise, and geospatial tools can help us make our systems part of the wider world, reducing harmful impacts and improving operations at the same time. Having geospatial data and the tools to work with it lets Microsoft deliver on the vision of a truly Planetary Computer, one that can add intelligence and analytics to the interfaces between our systems and the broader environment.
{kind=link}
How to use frozen collections in C# 12 Jun 2025, 11:00 am
Developers often grapple with the available options in their quest to use the most suitable data structure for their application. The various collections in C# offer different ways to store data objects and search, sort, insert, modify, delete, and iterate across those objects. For example, the .NET Base Class Library (BCL) provides support for read-only, immutable, and frozen collections. Each of these collection types has distinct use cases.
Read-only collections provide read-only access to data in a mutable collection, i.e., a collection that can be altered by other means. Immutable collections are collections that preserve their structure, meaning they cannot be altered after creation. An immutable collection enables thread-safe modifications to the data by creating a new instance of the collection each time you change its data. Typical examples of immutable collections are ImmutableStack, ImmutableList, and ImmutableHashSet.
Frozen collections, including the FrozenSet and FrozenDictionary classes, were introduced in .NET 8. These are immutable collections that have been optimized for fast look-ups. In addition, frozen collections provide a thread-safe way to access an immutable collection. In this article, we’ll examine how we can use frozen collections in C#. We’ll also look at the performance advantages of frozen collections by comparing the look-up speed of a FrozenSetto other collection types.
Create a console application project in Visual Studio
First off, let’s create a .NET Core console application project in Visual Studio. Assuming Visual Studio 2022 is installed in your system, follow the steps outlined below to create a new .NET Core console application project.
- Launch the Visual Studio IDE.
- Click on “Create new project.”
- In the “Create new project” window, select “Console App” from the list of templates displayed.
- Click Next.
- In the “Configure your new project” window, specify the name and location for the new project.
- Specify the Solution name for your project and select the check box to place the solution and the project files in the same directory.
- Click Next.
- In the “Additional information” window shown next, choose “.NET 9.0 (Standard Term Support)” as the framework version you would like to use.
- Ensure that the check boxes for enabling container support, specifying container build type, and enabling native AOT publish are unchecked. We won’t be using any of these features in this example.
- Click Create.
We’ll use this .NET 9 Core console application project to work with frozen collections in the subsequent sections of this article.
What are frozen collections? Why do we need them?
Frozen collections refer to a specific type of collection that blends the benefits of immutability and fast read performance. The term immutable here implies that these collections cannot be altered after they are created, thereby ensuring thread safety. Frozen collections eliminate the need to synchronize code that uses these collections in concurrent applications, i.e., applications that handle multiple threads simultaneously.
The System.Collections.Frozen namespace in .NET 8 introduces two new collection classes, FrozenSet and FrozenDictionary. “Frozen” here implies that the collections are immutable. You cannot change these collections once an instance of these classes has been created. These new collection classes enable you to perform faster look-ups and enumerations using methods such as TryGetValue() and Contains().
Key features of frozen collections in .NET Core
These are the key features of frozen collections in .NET Core:
- Immutability: Because frozen collections are immutable, you cannot alter them after they are created. As a result, your application’s data will remain thread-safe and consistent without requiring the use of synchronization techniques.
- Performance optimization: Frozen collections allow only read access, which reduces their memory footprint or overhead during initialization while improving lookup times. Hence, these collections are a great choice when your application needs frequent read-only access to data.
- Thread safety: Thanks to their immutable nature, frozen collections are thread-safe, allowing multiple threads to access the same frozen collection simultaneously without encountering race conditions or synchronization issues.
- Simplicity: Frozen collections are easy to use. You can easily integrate frozen collections into your application because their APIs are the same as the APIs of traditional collections.
Types of frozen collections in .NET Core
Basically, there are two types of frozen collections in .NET Core:
FrozenDictionary: AFrozenDictionaryrepresents a read-only dictionary that is optimized for fast searches. You can use this collection when the collection needs to be created once and read frequently.FrozenSet: AFrozenSetrepresents a read-only immutable set optimized for fast searches and enumeration. Like aFrozenDictionary, you cannot alter this collection after creation.
Because both FrozenSet and FrozenDictionary are read-only collections, you cannot add, change, or remove items in these collections.
Create frozen collections in C#
The following code snippet shows how you can create a FrozenSet from a HashSet instance, populate it with sample data, and then search for an item inside it. Recall that a HashSet is an unordered collection of unique elements that supports set operations (union, intersection, etc.) and uses a hash table for storage.
var hashSet = new HashSet { "A", "B", "C", "D", "E" };
var frozenSet = hashSet.ToFrozenSet();
bool isFound = frozenSet.TryGetValue("A", out _);
In the preceding code snippet, the ToFrozenSet() method is used to convert a HashSet instance to a FrozenSet instance. The method TryGetValue() will return true in this example because the data searched for is present in the collection.
The following code shows how you can create a FrozenDictionary, store data in it, and search for a particular key in the collection.
var dictionary = new Dictionary
{
{ 1, "A" },{ 2, "B" },{ 3, "C" },{ 4, "D" },{ 5, "E" }
};
var frozenDictionary = dictionary.ToFrozenDictionary();
bool isFound = dictionary.TryGetValue(7, out _);
When the above code is executed, the TryGetValue method will return false because the key 7 is not available in the collection.
Benchmarking performance of frozen collections in .NET Core
Let us now benchmark the performance of a frozen collection, specifically a FrozenSet, against other collection types using the BenchmarkDotNet library. For comparison, we’ll use a List, a HashSet, and an ImmutableHashSet.
Recall that a List is a mutable, strongly-typed, dynamically-sized, ordered collection of elements (even duplicates), and that a HashSet is a mutable, array-based collection of unique elements that is optimized for fast look-ups. Note that the time complexity for searching an item in a HashSet is O(1), compared to a time complexity of O(n) for a List (where n is the number of elements in the collection). Clearly, a HashSet is useful in cases where quick access is necessary. On the downside, a HashSet consumes more memory than a List and cannot include duplicate elements. You should use a List if you want to store an ordered collection of items (possibly duplicates) and where resource consumption is a constraint.
An ImmutableHashSet is the immutable counterpart of a HashSet, i.e., an array-based collection of unique elements that cannot be changed once created. Note that, whereas a HashSet is a mutable, array-based hash bucket optimized for fast searches, an ImmutableHashSet is a persistent data structure that uses AVL trees for immutability. Because this introduces additional overhead, searches of an ImmutableHashSet are much slower than searches of a HashSet.
Install BenchmarkDotNet
To use BenchmarkDotNet, you must first install the BenchmarkDotNet package. You can do this either via the NuGet Package Manager in the Visual Studio IDE, or by executing the following command at the NuGet Package Manager Console:
Install-Package BenchmarkDotNet
Create a benchmark class
In the console application project we created earlier, create a class named CollectionPerformanceBenchmark in a file with the same name and a .cs extension as shown below.
[MemoryDiagnoser]
public class CollectionPerformanceBenchmark
{
[GlobalSetup]
public void SetupData()
{
}
}
In the preceding code snippet, the attribute MemoryDiagnoser has been attached to the CollectionPerformanceBenchmark class to include memory consumption metrics in our benchmark results. The SetupData method is where we will write the initialization code for our benchmark, i.e., the code to create our collections, populate them with dummy data, and so on. The [GlobalSetup] attribute is used to ensure that SetupData method is executed before any benchmark methods.
Write the initialization code
The following code snippet implements the SetupData method that initializes each of the collection instances and populates them with data.
[GlobalSetup]
public void SetupData()
{
list = Enumerable.Range(0, NumberOfItems).ToList();
hashSet = Enumerable.Range(0, NumberOfItems).ToHashSet();
immutableHashSet = Enumerable.Range(0, NumberOfItems).ToImmutableHashSet();
frozenSet = Enumerable.Range(0, NumberOfItems).ToFrozenSet();
}
Write the benchmark code
Next, we must write the necessary code for benchmarking. Each method that contains code for benchmarking should be decorated using the [Benchmark] attribute as shown below.
[Benchmark(Baseline = true)]
public void SearchList()
{
for (var i = 0; i
In the preceding code snippet, the SearchList method has been decorated using the [Benchmark] attribute and has been set as the baseline against which the performance of the other benchmark methods will be compared.
The complete source code of our CollectionPerformanceBenchmark benchmarking class is given below for reference. Note that it includes the necessary code for the other benchmark methods (SearchFrozenSet, SearchHashSet, and SearchImmutableHashSet), which are implemented in much the same way we implemented the SearchList method.
[MemoryDiagnoser]
public class CollectionPerformanceBenchmark
{
private const int NumberOfItems = 1000;
private List list;
private FrozenSet frozenSet;
private HashSet hashSet;
private ImmutableHashSet immutableHashSet;
[GlobalSetup]
public void SetupData()
{
list = Enumerable.Range(0, NumberOfItems).ToList();
hashSet = Enumerable.Range(0, NumberOfItems).ToHashSet();
immutableHashSet = Enumerable.Range(0, NumberOfItems).ToImmutableHashSet();
frozenSet = Enumerable.Range(0, NumberOfItems).ToFrozenSet();
}
[Benchmark(Baseline = true)]
public void SearchList()
{
for (var i = 0; i
Faster searches in frozen collections
When you run the benchmarks above, you’ll notice the distinct performance differences between searching data in a frozen collection (in this case a FrozenSet) compared to a normal collection such as a List as shown in Figure 1.
List, FrozenSet, HashSet, and ImmutableHashSet). IDG
As you can see in the benchmark results, searching a FrozenSet is not only much faster than searching a List, it is even faster than searching a HashSet. So, when you need fast look-ups in a mutable set, use a HashSet. When you need fast look-ups in an immutable set, use a FrozenSet. Keep in mind that, because a FrozenSet is immutable, it incurs a significantly higher overhead cost of creation compared to a HashSet.
Performance and scalability have improved with every release of .NET Core. The introduction of frozen collections heralds a new approach to efficiently searching data, and future releases will include more such improvements.
{kind=link}
Apple rolls out Swift, SwiftUI, and Xcode updates 12 Jun 2025, 4:00 am
Apple at its Worldwide Developers Conference (WWDC) this week announced the latest advancements for the Swift language, SwiftUI framework, and Xcode IDE. Highlights include concurrency enhancements and improved C++ and Java interoperability for Swift, compilation caching for Xcode, and new design APIs in SwiftUI.
With Swift 6.2, developers can incrementally adopt Swift in existing C++, C, and Objective-C apps to make code safer and more efficient, Apple said. The swift-java interoperability project now allows developers to incorporate Swift in Java code. Updates to concurrency make asynchronous and concurrent code easier to write correctly. Inline arrays enable developers to declare fixed-size arrays, which allows for compile-time optimizations. A new Span type provides an alternative to unsafe buffer pointers. Apple also introduced Containerization, an open-source project written in Swift for building and running Linux containers on macOS and Apple silicon.
With Xcode 26, in addition to built-in support for ChatGPT, Xcode now allows developers to use generative AI powered by a large language model of their choice, either by using API keys from other providers or running local models on their Mac (Apple silicon required). Coding Tools now provides suggestions to help developers quickly write documentation, fix an issue, or make a code change, Apple said. Compilation caching, introduced as an opt-in feature, speeds up iterative build and test cycles for Swift and C-family languages. Compilation caching caches the results of compilations that were produced for a set of source files and, when it detects that the same set of source files are getting re-compiled, speeds up builds by providing prior compilation results directly from the cache.
Xcode 26 also includes a preview of a new implementation for Swift package builds, based on shared code with Swift Package Manager. This should improve the consistency and stability of builds across the package manager and Xcode, Apple said.
Finally, SwiftUI, Apple’s user interface toolkit, has been updated to support Apple’s new Liquid Glass, which Apple describes as a dynamic design material that combines the optical properties of glass with a sense of fluidity. SwiftUI also adds new APIs for immersive spaces in visionOS, new WebKit APIs for bringing web content into Swift apps, and 3D Swift Charts based on RealityKit, Apple’s 3D and augmented reality framework.
{kind=link}
Salesforce changes Slack API terms to block bulk data access for LLMs 12 Jun 2025, 2:20 am
Salesforce’s Slack platform has changed its API terms of service to stop organizations from using Large Language Models (LLMs) to ingest the platform’s data as part of its efforts to implement better enterprise data discovery and search.
While it sounds like a largely technical tweak, it could nevertheless have profound implications for a raft of internal and third-party AI apps that organizations have started using to tame data sprawl.
The new policy was outlined under the new heading Data usage in the latest terms of service, published on May 29. It prohibits the bulk export of Slack data via the API, and explicitly states that data accessed via Slack APIs can no longer be used to train LLMs. Instead, organizations will have to rely on the company’s new Real-Time Search API, which offers search only from within Slack itself.
{kind=link}
Databricks aims to optimize agent building for enterprises with Agent Bricks 11 Jun 2025, 3:57 pm
Databricks has released a beta version of a new agent building interface to help enterprises automate and optimize the agent building process.
Agent Bricks is a new generative AI-driven interface combining technologies developed by MosaicML, which Databricks acquired in 2023, includng TAO, synthetic data generation API, and the Mosaic Agent platform.
However, it is not a rebranded Mosaic Agent Platform, said Robert Kramer, principal analyst at Moor Insights and Strategy, but rather a higher-level, automated abstraction that streamlines agent development for enterprises.
Agent Bricks is intended for use mainly by data professionals and developers, and can be accessed via the “Agent” button in the lakehouse software provider’s Data Intelligence platform.
Using Agent Bricks
Users begin by selecting from a variety of task types they want to execute via agents, such as extracting information from documents, creating a conversational agent, or building a multi-agent workflow system.
Next, they provide a high-level description of the type of agent or agents they are trying to build and attach different knowledge sources for the required task.
Agent Bricks then automatically creates a custom evaluation benchmark for the specified task, said Databricks’ CTO of neural networks, Hanlin Tang, said, giving the example of an agent for customer support.
“We will build a custom LLM judge that’ll measure whether the customer will churn during that support call, or the customer is happy or unhappy. Once we have the benchmark for the task, Agent Bricks then looks at how to optimize the agent itself,” Tang added.
During the optimization phase, Agent Bricks uses techniques including synthetic data generation, prompt engineering, model selection, and fine tuning to deliver an agent that is optimized for quality and cost that enterprises can deploy.
Optimization
Databricks is pitching Agent Bricks as a way to take the complexity out of the process of building agents, as most enterprises don’t have either the time or the talent to go through an iterative process of building and matching an agent to a use case.
“Agent Bricks is notable for automating the agent creation lifecycle from evaluation to optimization, an area where most competitors focus on hosting or orchestrating models rather than lifecycle automation,” said Kramer.
“Snowflake Cortex, for example, supports hosted AI agents but lacks synthetic data and auto-optimization features. AWS Bedrock and Azure OpenAI provide model hosting and tooling but do not offer integrated evaluation and cost tuning at this level,” he said.
Teradata doesn’t offer direct agent-building capabilities either, while Salesforce’s Agentforce platform, though offering evaluation tools for agents, doesn’t automate the process and leaves a lot of engineering to data professionals and developers.
At Constellation Research, Principal Analyst Michael Ni pointed out that though Agent Bricks automates and optimizes the agent building process, it will not replace data engineers, but rather help them save them time in building agentic applications.
“Data engineers still oversee integration and deployment, but they’re no longer blocked by repetitive, low-value scaffolding work,” Ni said, adding he doesn’t see Agent Bricks as a point-and-click tool for non-technical users.
Support for MCP
As part of the new interface, Databricks is adding some templatized agents that enterprises can use out-of-the-box: Information Extraction Agents for getting structured data from unstructured data, Knowledge Assistant Agent for supporting conversational agents, Multi-Agent Supervisor for building multi-agent systems, and Custom LLM Agent for custom tasks.
These agents are use-case templates or archetypes designed for common enterprise scenarios and act as starting points that can be customized based on organizational data and performance requirements, rather than rigid building blocks or mandatory frameworks.
Agent Bricks also supports Anthropic’s Model Context Protocol (MCP), an increasingly popular framework for connecting agents across disparate technology stacks or systems.
The Multi-Agent supervisor inside Agent Bricks can read and accept an MCP server as an agent, making agents on other systems accessible, said Databricks’ Tang, adding that an agent produced on Agent Bricks can also be exposed as an endpoint in order to connect to other agent systems.
Databricks is also working on support for Google’s A2A protocol, Tang said, cautioning that development is in “very early days.”
A different approach to agent lifecycle management
Agent Bricks takes a different approach to agent lifecycle management when compared to similar offerings from other vendors.
While most vendors have built agent lifecycle management tools inside their agent builders, Databricks is leveraging Unity Catalog and MLflow 3.0 for managing agents built on Agent Bricks — meaning ongoing AgentOps tasks, such as, monitoring, evaluation, deployment, and rollback, are handled by MLflow 3.0 and Unity Catalog.
Snowflake, on the other hand, integrates agent lifecycle management within Cortex, while AWS and Azure embed monitoring directly into their agent environments.
Kramer said that enterprises with smaller teams may think twice before adopting Agent Bricks as Databricks’ approach requires users to work across multiple services. “This separation may slow adoption for teams expecting a unified toolset, especially those new to Databricks’ platform,” he said.
But, said Bradley Shimmin, the lead of the data and analytics practice at The Futurum Group, some enterprises may align with Databricks’ approach towards agent lifecycle management: an agent, like a data table or machine learning model, is an asset and should be governed by the same central catalog.
{kind=link}
Building an analytics architecture for unstructured data and multimodal AI 11 Jun 2025, 3:10 pm
Data scientists today face a perfect storm: an explosion of inconsistent, unstructured, multimodal data scattered across silos – and mounting pressure to turn it into accessible, AI-ready insights. The challenge isn’t just dealing with diverse data types, but also the need for scalable, automated processes to prepare, analyze, and use this data effectively.
Many organizations fall into predictable traps when updating their data pipelines for AI. The most common: treating data preparation as a series of one-off tasks rather than designing for repeatability and scale. For example, hardcoding product categories in advance can make a system brittle and hard to adapt to new products. A more flexible approach is to infer categories dynamically from unstructured content, like product descriptions, using a foundation model, allowing the system to evolve with the business.
Forward-looking teams are rethinking pipelines with adaptability in mind. Market leaders use AI-powered analytics to extract insights from this diverse data, transforming customer experiences and operational efficiency. The shift demands a tailored, priority-based approach to data processing and analytics that embraces the diverse nature of modern data, while optimizing for different computational needs across the AI/ML lifecycle.
Tooling for unstructured and multimodal data projects
Different data types benefit from specialized approaches. For example:
- Text analysis leverages contextual understanding and embedding capabilities to extract meaning;
- Video pipelines processing employs computer vision models for classification;
- Time-series data uses forecasting engines.
Platforms must match workloads to optimal processing methods while maintaining data access, governance, and resource efficiency.
Consider text analytics on customer support data. Initial processing might use lightweight natural language processing (NLP) for classification. Deeper analysis could employ large language models (LLMs) for sentiment detection, while production deployment might require specialized vector databases for semantic search. Each stage requires different computational resources, yet all must work together seamlessly in production.
Representative AI Workloads
| AI Workload Type | Storage | Network | Compute | Scaling Characteristics |
| Real-time NLP classification | In-memory data stores; Vector databases for embedding storage | Low-latency (<100ms); Moderate bandwidth | GPU-accelerated inference; High-memory CPU for preprocessing and feature extraction | Horizontal scaling for concurrent requests; Memory scales with vocabulary |
| Textual data analysis | Document-oriented databases and vector databases for embedding; Columnar storage for metadata | Batch-oriented, high-throughput networking for large-scale data ingestion and analysis | GPU or TPU clusters for model training; Distributed CPU for ETL and data preparation | Storage grows linearly with dataset size; Compute costs scale with token count and model complexity |
| Media analysis | Scalable object storage for raw media; Caching layer for frequently- accessed datasets | Very high bandwidth; Streaming support | Large GPU clusters for training; Inference-optimized GPUs | Storage costs increase rapidly with media data; Batch processing helps manage compute scaling |
| Temporal forecasting, anomaly detection | Time-partitioned tables; Hot/cold storage tiering for efficient data management | Predictable bandwidth; Time-window batching | Often CPU-bound; Memory scales with time window size | Partitioning by time ranges enables efficient scaling; Compute requirements grow with prediction window. |
The different data types and processing stages call for different technology choices. Each workload needs its own infrastructure, scaling methods, and optimization strategies. This variety shapes today’s best practices for handling AI-bound data:
- Use in-platform AI assistants to generate SQL, explain code, and understand data structures. This can dramatically speed up initial prep and exploration phases. Combine this with automated metadata and profiling tools to reveal data quality issues before manual intervention is required.
- Execute all data cleaning, transformation, and feature engineering directly within your core data platform using its query language. This eliminates data movement bottlenecks and the overhead of juggling separate preparation tools.
- Automate data preparation workflows with version-controlled pipelines inside your data environment, to ensure reproducibility and free you to focus on modeling over scripting.
- Take advantage of serverless, auto-scaling compute platforms so your queries, transformations, and feature engineering tasks run efficiently for any data volume. Serverless platforms allow you to focus on transformation logic rather than infrastructure.
These best practices apply to structured and unstructured data alike. Contemporary platforms can expose images, audio, and text through structured interfaces, allowing summarization and other analytics via familiar query languages. Some can transform AI outputs into structured tables that can be queried and joined like traditional datasets.
By treating unstructured sources as first-class analytics citizens, you can integrate them more cleanly into workflows without building external pipelines.
Today’s architecture for tomorrow’s challenges
Effective modern data architecture operates within a central data platform that supports diverse processing frameworks, eliminating the inefficiencies of moving data between tools. Increasingly, this includes direct support for unstructured data with familiar languages like SQL. This allows them to treat outputs like customer support transcripts as query-able tables that can be joined with structured sources like sales records – without building separate pipelines.
As foundational AI models become more accessible, data platforms are embedding summarization, classification, and transcription directly into workflows, enabling teams to extract insights from unstructured data without leaving the analytics environment. Some, like Google Cloud BigQuery, have introduced rich SQL primitives, such as AI.GENERATE_TABLE(), to convert outputs from multimodal datasets into structured, queryable tables without requiring bespoke pipelines.
AI and multimodal data are reshaping analytics. Success requires architectural flexibility: matching tools to tasks in a unified foundation. As AI becomes more embedded in operations, that flexibility becomes critical to maintaining velocity and efficiency.
Learn more about these capabilities and start working with multimodal data in BigQuery.
{kind=link}
Databricks targets AI bottlenecks with Lakeflow Designer 11 Jun 2025, 3:00 pm
Databricks showcased a new no-code data management tool, powered by a generative AI assistant, at its ongoing Data + AI summit, which is designed to help enterprises eliminate data engineering bottlenecks slowing down AI projects.
Called Lakeflow Designer, the tool is designed to empower data analysts build no-code ETL (extract, transform, load) pipelines — a task, typically, left to data engineers who are always busy, thus creating a barrier to accelerate AI projects or uses cases, said Bilal Aslam, senior director of product management at Databricks. Lakeflow Designer is currently in preview.
While enterprises employ low-code or no-code tools for data analysts to curtail the load on data engineers, these tools lack governance and scalability, Aslam said, adding that Lakeflow Designer is designed to alleviate these challenges.
“Lakeflow Designer addresses a key data management problem: data engineering bottlenecks are killing AI momentum with disconnected tools across data ingestion, preparation, cleansing, and orchestration,” said Michael Ni, principal analyst at Constellation Research. “Lakeflow Designer blows the doors open by putting the power of a no-code tool in analysts’ hands, while keeping it enterprise safe.”
Ni called Lakeflow Designer the “Canva of ETL” — instant, visual, AI-assisted development of data pipelines — yet under the hood, it’s Spark SQL at machine scale, secured by Unity Catalog.
Advisory firm ISG’s director of software research, Matt Aslett, said the new tool is expected to reduce the burden on data engineering teams but pointed out that data analysts are highly likely to still be working with data engineering teams for use cases that have more complex integration and transformation requirements that require additional expertise.
Lakeflow Designer makes collaboration between data analysts and engineers in an enterprise easier as it allows sharing of metadata and CI/CD pipelines, meaning these can be inspected, edited by engineers if required, Ni said.
The tool also supports Git and DevOps flows, providing lineage, access control, and auditability, Ni added.
Like Aslett, the analyst pointed out that the new tool is likely to aid enterprises in less complex use cases, such as regional margin tracking, compliance, metric aggregation, retention window monitoring, and cohorting, although it supports custom development.
Lakeflow Designer is part of Lakeflow, which will now be generally available. Lakeflow has three modules — Lakeflow Connect, Lakeflow Declarative Pipelines, and Lakeflow Jobs. Designer is integrated within Declarative Pipelines.
United in purpose, divided in approach
Lakeflow Designer, despite being very similar to rival Snowflake’s Openflow, differs in its approach, analysts say.
“Lakeflow and OpenFlow reflect two philosophies: Databricks integrates data engineering into a Spark-native, open orchestration fabric, while Snowflake’s OpenFlow offers declarative workflow control with deep Snowflake-native semantics. One favors flexibility and openness; the other favors consolidation and simplicity,” Ni said.
Both the offerings also differ in maturity, ISG’s Aslett said. While Snowflake’s OpenFlow is relatively new, Lakeflow has matured in functionality over the years, with Designer being its latest tool. “The Connect capabilities were acquired along with Arcion in 2023. Declarative pipelines functionality is the evolution of DLT (Delta Live Tables), and Jobs is the evolution of Databricks Workflows,” Aslett added.
Separately, Databricks also released another pro-code integrated development environment (IDE) for data engineers, which unifies the data engineer’s full pipeline lifecycle — code, DAGs, sample data, and debugging — all in one integrated workspace.
Releasing Lakeflow Designer and the new IDE together is a strategic play, according to Ni, as the lakehouse provider is targeting both ends of the pipeline maturity curve — low-code to move fast and the full IDE to scale and maintain pipelines.
{kind=link}
Page processed in 0.309 seconds.
Powered by SimplePie 1.3.1, Build 20130517180413. Run the SimplePie Compatibility Test. SimplePie is © 2004–2025, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.